
Machine Learning (ML) is one of the most transformative technologies of the 21st century, reshaping industries, redefining how we interact with technology, and revolutionizing decision-making processes. From voice assistants like Alexa and Siri to recommendation engines on Netflix and YouTube, machine learning is all around us—working silently behind the scenes to make our lives easier and more efficient. But what exactly is machine learning, and how does it work?
Key Takeaways
- Machine learning is a branch of AI that enables systems to learn from data and make decisions.
- The main types include supervised, unsupervised, and reinforcement learning.
- The process involves data collection, preprocessing, algorithm selection, training, evaluation, and deployment.
- Applications span across industries, from healthcare to finance, and transportation to marketing.
- Challenges such as bias, data quality, and transparency must be addressed for responsible ML deployment.
Understanding Machine Learning: A Simple Definition
Machine learning is a subfield of artificial intelligence (AI) that focuses on creating algorithms and statistical models that allow computers to perform specific tasks without using explicit instructions. Instead, these systems learn patterns and make decisions based on data.
In simpler terms, machine learning enables computers to learn from experience—just like humans do. It uses data to make predictions or decisions without being specifically programmed for every scenario.
The Core Concept: Learning from Data
The fundamental process in machine learning involves:
- Input Data – Feeding historical or real-time data to the algorithm.
- Pattern Recognition – The model identifies patterns, trends, or correlations in the data.
- Prediction or Decision-Making – The system applies learned patterns to make predictions on new, unseen data.
- Feedback and Optimization – The model improves over time with more data and feedback.
Types of Machine Learning
Machine learning is broadly categorized into three main types:
Supervised Learning
- Definition: The model is trained on a labeled dataset, which means the input data is paired with the correct output.
- Examples:
- Email spam detection
- Credit scoring
- Predicting house prices
- Popular Algorithms: Linear Regression, Decision Trees, Support Vector Machines (SVM), Random Forest.
Unsupervised Learning
- Definition: The algorithm works with unlabeled data and tries to find patterns or groupings without predefined categories.
- Examples:
- Customer segmentation
- Market basket analysis
- Anomaly detection
- Popular Algorithms: K-Means Clustering, Hierarchical Clustering, Principal Component Analysis (PCA).
Reinforcement Learning
- Definition: The model learns by interacting with an environment and receiving rewards or penalties based on its actions.
- Examples:
- Robotics
- Game playing (e.g., AlphaGo)
- Dynamic pricing systems
- Popular Techniques: Q-Learning, Deep Q-Networks (DQNs), Policy Gradients.
How Machine Learning Works: Step-by-Step Process
Let’s break down the process:
Data Collection
Data is the foundation of any ML system. This can include structured data (like spreadsheets) or unstructured data (like images, videos, and text).
Data Preprocessing
Before training the model, the data must be cleaned and formatted. This includes:
- Handling missing values
- Removing duplicates
- Normalizing values
- Encoding categorical variables
Choosing the Right Algorithm
The type of data and the problem to be solved determine the choice of algorithm. For instance:
- Use Linear Regression for predicting continuous values.
- Use Classification algorithms for categorizing data.
Model Training
The training phase involves feeding data into the algorithm so it can learn patterns. It adjusts internal parameters to minimize errors during prediction.
Model Evaluation
After training, the model is evaluated using testing datasets that it hasn’t seen before. Key metrics include:
- Accuracy
- Precision
- Recall
- F1 Score
- ROC-AUC Curve
Tuning and Optimization
If the model doesn’t perform well, it might need:
- Hyperparameter tuning
- Feature engineering
- Using a different algorithm or architecture
Deployment and Monitoring
Once the model meets performance criteria, it’s deployed into a live environment. Regular monitoring ensures it continues to perform accurately as new data comes in.
Popular Applications of Machine Learning
Machine learning is already embedded in many real-world applications:
Healthcare
- Disease diagnosis using imaging
- Predicting patient readmissions
- Drug discovery and genomics
Finance
- Fraud detection
- Credit scoring
- Algorithmic trading
E-commerce and Retail
- Personalized product recommendations
- Inventory forecasting
- Customer lifetime value prediction
Transportation
- Self-driving cars
- Route optimization
- Predictive maintenance
Social Media and Marketing
- Targeted advertising
- Sentiment analysis
- Content recommendation
What Are the Different Types of Machine Learning Algorithms?
Definition: This topic explores the classification of machine learning algorithms into groups such as regression, classification, clustering, dimensionality reduction, and reinforcement learning. It provides insights into when and why to use each algorithm, such as Decision Trees, Neural Networks, or K-Means.
How Is Deep Learning Different from Traditional Machine Learning?
Definition: Deep learning is a subset of machine learning that uses multi-layered neural networks to model complex patterns. Unlike traditional ML, which often requires feature engineering, deep learning models learn features automatically from raw data like images or audio.
What Are Neural Networks and How Do They Work?
Definition: Neural networks are computing systems inspired by the human brain, consisting of layers of nodes (neurons). They process input data through weighted connections and activation functions to make predictions or classifications.
What Is the Role of Data in Machine Learning?
Definition: Data is the fuel of ML. This topic discusses the importance of high-quality, clean, and diverse datasets and how data preprocessing (e.g., normalization, transformation) impacts model performance.
What Is Overfitting and Underfitting in Machine Learning
Definition: Overfitting occurs when a model learns the training data too well, including noise, which reduces its generalization ability. Underfitting happens when the model fails to capture underlying patterns. This topic explains how to identify and prevent both.
How Do You Evaluate Machine Learning Models?
Definition: Evaluation involves testing models with unseen data using performance metrics such as accuracy, precision, recall, F1 score, and confusion matrix. This topic also includes cross-validation techniques and error analysis.
What Is Feature Engineering and Why Is It Important?
Definition: Feature engineering is the process of selecting, modifying, or creating new variables (features) from raw data to improve model accuracy. It’s a critical step in building effective machine learning models.
What Are Hyperparameters and How Do You Tune Them?
Definition: Hyperparameters are external configurations for learning algorithms (e.g., learning rate, tree depth). Tuning them using techniques like grid search or random search significantly affects model performance.
What Is Transfer Learning in Machine Learning?
Definition: Transfer learning involves using a pre-trained model on one task and adapting it to a different but related task. It’s especially useful when data is scarce or training from scratch is computationally expensive.
What Is Explainable AI (XAI) and Why Does It Matter?
Definition: Explainable AI focuses on making ML model decisions transparent and understandable to humans. This is crucial in fields like healthcare or finance, where interpretability is necessary for trust and compliance.
What Is the Role of Ethics in Machine Learning?
Definition: Ethical ML involves fairness, accountability, transparency, and privacy. This topic covers bias in algorithms, data misuse, and the societal impact of AI-driven decisions.
What Is Computer Vision in Machine Learning?
Definition: Computer vision is a subfield of ML where systems interpret and analyze visual data like images and videos. It’s used in facial recognition, object detection, and medical imaging.
What Is Natural Language Processing (NLP)?
Definition: NLP is the intersection of machine learning and linguistics that enables machines to understand, interpret, and generate human language. Applications include chatbots, translators, and sentiment analysis.
What Is Reinforcement Learning and Where Is It Used?
Definition: Reinforcement learning is a learning paradigm where agents interact with an environment and learn policies through rewards and penalties. It’s used in robotics, gaming (like AlphaGo), and autonomous systems.
What Is Anomaly Detection in Machine Learning?
Definition: Anomaly detection involves identifying rare events or observations that differ significantly from the majority. It’s commonly used in fraud detection, network security, and health monitoring.
Benefits of Machine Learning

- Automation of tasks
- Improved decision-making
- Personalization at scale
- Real-time analysis and predictions
- Cost and time savings
Challenges and Limitations
Despite its benefits, ML has some key challenges:
- Data dependency: High-quality data is a must.
- Bias and fairness: Models may reinforce existing biases.
- Transparency: Some models, like deep learning, are “black boxes”.
- Security risks: Adversarial attacks can fool ML models.
What Is Supervised Learning and How Is It Used?
Definition: Supervised learning is a type of machine learning where the model is trained on a labeled dataset, meaning each input comes with an associated correct output. The algorithm learns to map inputs to outputs and can predict outcomes for new data.
Applications: Spam detection, image classification, loan approval systems.
What Is Unsupervised Learning and What Problems Does It Solve?
Definition: Unsupervised learning deals with unlabeled data. The model tries to find structure, patterns, or groupings without prior knowledge of outputs.
Applications: Customer segmentation, market basket analysis, social network analysis.
What Is Semi-Supervised Learning?
Definition: Semi-supervised learning combines a small amount of labeled data with a large amount of unlabeled data during training. It’s useful when labeling is costly or time-consuming.
Applications: Medical imaging, speech recognition, document classification.
What Is Self-Supervised Learning?
Definition: Self-supervised learning is an emerging technique where the model generates its own labels from input data. It’s particularly popular in deep learning fields like NLP and computer vision.
Applications: Pretraining large language models (e.g., GPT), image recognition without human annotation.
What Are Decision Trees in Machine Learning?
Definition: A decision tree is a flowchart-like model that splits data into branches to make predictions. It uses conditions at each node to classify inputs.
Advantages: Easy to interpret, works well for both classification and regression.
What Are Ensemble Methods in Machine Learning
Definition: Ensemble methods combine multiple models (like decision trees) to improve prediction accuracy. Common techniques include bagging, boosting, and stacking.
Examples: Random Forest, Gradient Boosting Machines (GBM), AdaBoost.
What Are Support Vector Machines (SVM)?
Definition: SVM is a supervised learning model that finds the optimal hyperplane to separate data into classes. It’s powerful in high-dimensional spaces and effective for binary classification problems.
Use Cases: Text classification, image recognition, bioinformatics.
What Are Convolutional Neural Networks (CNNs)?
Definition: CNNs are deep learning models particularly effective at processing image data. They use convolutional layers to detect local patterns (edges, textures, shapes) in images.
Applications: Facial recognition, object detection, medical image analysis.
What Are Recurrent Neural Networks (RNNs)?
Definition: RNNs are neural networks designed for sequence data. They maintain a memory of previous inputs, making them suitable for time-series analysis and language modeling.
Applications: Speech recognition, machine translation, stock price prediction.
What Is Dimensionality Reduction in Machine Learning?
Definition: Dimensionality reduction simplifies data by reducing the number of features while preserving relevant information. It helps prevent overfitting and improves model performance.
Techniques: PCA (Principal Component Analysis), t-SNE, LDA (Linear Discriminant Analysis).
What Is Model Interpretability and Why Is It Important?
Definition: Interpretability refers to how easily a human can understand the reasoning behind a model’s predictions. It’s essential in sensitive applications like healthcare, legal systems, and finance.
Tools: SHAP, LIME, partial dependence plots.
What Is Model Drift and How Can You Detect It?
Definition: Model drift occurs when the statistical properties of input data change over time, reducing a model’s accuracy.
Types: Concept drift (changing target), data drift (input distribution change).
Detection: Using monitoring tools and periodic retraining.
What Is Federated Learning?
Definition: Federated learning is a decentralized form of machine learning where models are trained across multiple devices without centralizing data. It helps preserve privacy.
Applications: Predictive keyboards, healthcare apps, IoT devices.
What Is Data Augmentation in Machine Learning?
Definition: Data augmentation artificially increases the size and diversity of training datasets by creating modified versions of existing data.
Examples: Rotating images, adding noise, translating text.
Use Cases: Especially useful in deep learning for image and text tasks.
What Is the Role of Big Data in Machine Learning?
Definition: Big data refers to extremely large datasets that require distributed computing to process. Machine learning models trained on big data can uncover deep insights and trends.
Tools: Apache Hadoop, Spark MLlib, AWS Sagemaker.
What Is Model Overfitting and Why Is It a Problem in Machine Learning?
Definition:
Overfitting occurs when a machine learning model learns not only the underlying patterns in the training data but also the noise and irrelevant details. This results in a model that performs extremely well on training data but poorly on new, unseen data. The core issue with overfitting is that the model becomes too complex, memorizing the training examples rather than generalizing from them.
Overfitting can be diagnosed by comparing training and validation performance—when the training accuracy is very high but validation accuracy is significantly lower, it’s a clear sign. Regularization techniques (like L1/L2 penalties), pruning, early stopping, and collecting more training data are common ways to mitigate overfitting.
What Is Gradient Descent and How Does It Power Machine Learning?
Definition:
Gradient Descent is an optimization algorithm used to minimize the error or loss of a machine learning model by adjusting its parameters (weights). It works by computing the gradient (i.e., the derivative) of the loss function with respect to each model parameter and moving in the direction opposite the gradient to reduce the loss.
In simple terms, imagine trying to find the lowest point in a valley blindfolded—you take small steps downhill based on the steepness beneath your feet. That’s gradient descent in action. It comes in several variants: batch gradient descent (entire dataset at once), stochastic gradient descent (one sample at a time), and mini-batch gradient descent (subset of data).
It’s especially vital in training neural networks, where the optimization surface can be highly complex and non-linear.
What Are Activation Functions in Neural Networks and Why Are They Important?
Definition:
Activation functions introduce non-linearity into neural networks, enabling them to learn complex patterns. Without activation functions, a neural network—even with multiple layers—would behave like a simple linear regression model, unable to model complex relationships.
Common activation functions include:
- ReLU (Rectified Linear Unit): Outputs zero for negative values and the value itself for positive inputs. It’s widely used due to simplicity and efficiency.
- Sigmoid: Maps values between 0 and 1, often used in binary classification.
- Tanh: Similar to sigmoid but maps inputs to the range of -1 to 1.
- Softmax: Converts outputs to probabilities and is used in multi-class classification problems.
The choice of activation function significantly affects the learning process, convergence speed, and model accuracy.
What Is the Bias-Variance Tradeoff in Machine Learning?
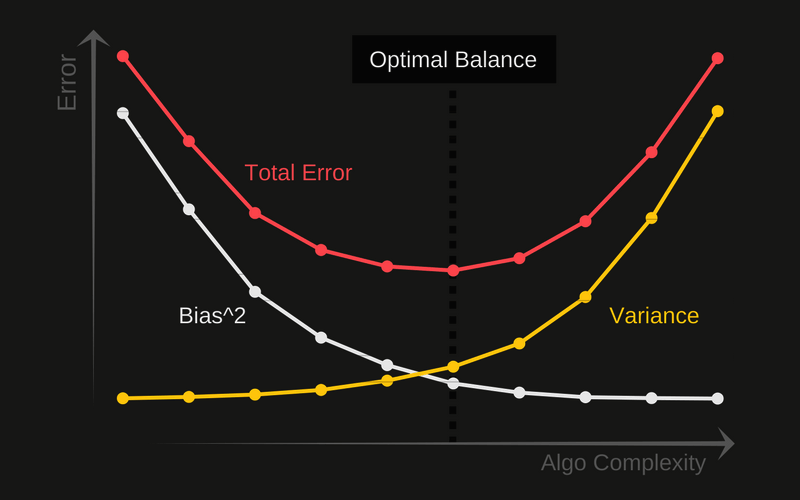
Definition:
The bias-variance tradeoff is a fundamental concept in machine learning that describes the tradeoff between two sources of error when building models:
- Bias: Error due to overly simplistic assumptions in the learning algorithm. High bias leads to underfitting.
- Variance: Error due to the model’s sensitivity to small fluctuations in the training data. High variance leads to overfitting.
An optimal model achieves a balance: low bias to ensure the model learns relevant patterns, and low variance to ensure it generalizes well to new data. Techniques such as cross-validation, regularization, and ensemble learning are used to manage this tradeoff effectively.
What Is Cross-Validation and Why Is It Essential in Model Evaluation?
Definition:
Cross-validation is a resampling technique used to evaluate machine learning models on limited data. It helps assess how the model will generalize to an independent dataset and avoids the pitfalls of overfitting or underfitting during training.
The most common form is k-fold cross-validation, where the dataset is divided into k equal parts. The model is trained on k-1 parts and tested on the remaining part. This process is repeated k times, and the results are averaged to get a robust estimate of model performance.
Cross-validation is especially valuable when you have a small dataset or want to compare different algorithms or hyperparameter settings reliably.
What Is Feature Selection and How Does It Improve Model Performance?
Definition:
Feature selection is the process of identifying and selecting the most relevant input variables (features) for a machine learning model. It plays a crucial role in reducing model complexity, improving performance, and enhancing interpretability.
There are three main types of feature selection:
- Filter methods: Use statistical techniques to rank features (e.g., correlation).
- Wrapper methods: Use model performance as a guide (e.g., recursive feature elimination).
- Embedded methods: Perform selection during model training (e.g., LASSO regularization).
By removing irrelevant or redundant features, models become faster, less prone to overfitting, and easier to interpret.
What Are Loss Functions and Why Are They Important in Machine Learning?
Definition:
A loss function quantifies how well a machine learning model’s predictions match the actual outcomes. It’s the objective the learning algorithm tries to minimize. The lower the loss, the better the model is performing.
Common loss functions include:
- Mean Squared Error (MSE): Used for regression tasks.
- Binary Cross-Entropy: Used for binary classification.
- Categorical Cross-Entropy: Used for multi-class classification.
- Hinge Loss: Common in support vector machines.
Choosing the right loss function is critical because it directly affects how the model learns and what it optimizes for.
What Is Data Normalization and Why Is It Crucial for Training Models?
Definition:
Data normalization is a preprocessing technique that scales input data into a standard range (typically 0 to 1 or -1 to 1). It ensures that all features contribute equally to the model’s learning process.
Without normalization, features with large values could disproportionately influence the model, leading to biased learning and slower convergence in optimization algorithms like gradient descent.
Common normalization methods include:
- Min-Max Scaling
- Z-score Standardization
- Robust Scaling (uses median and IQR)
Normalization is especially vital in algorithms like k-nearest neighbors (KNN) and neural networks, where distance and scale significantly affect performance.
What Is a Confusion Matrix in Machine Learning Evaluation?
Definition:
A confusion matrix is a tabular visualization tool used to evaluate the performance of classification models. It compares the predicted labels with the true labels to provide a detailed breakdown of how the model is performing.
It includes:
- True Positives (TP): Correctly predicted positive cases.
- False Positives (FP): Incorrectly predicted positive cases.
- True Negatives (TN): Correctly predicted negative cases.
- False Negatives (FN): Missed positive cases.
From this, key metrics like accuracy, precision, recall, and F1 score can be calculated. It’s especially useful when dealing with imbalanced datasets where overall accuracy can be misleading.
What Are Autoencoders in Machine Learning and What Are They Used For?
Definition:
Autoencoders are a type of neural network used primarily for unsupervised learning. They are designed to learn efficient codings of input data by compressing the input into a lower-dimensional space (encoding) and then reconstructing the output (decoding).
They consist of three parts:
- Encoder: Compresses the input.
- Bottleneck: Holds the compressed knowledge.
- Decoder: Reconstructs the input from the encoded version.
Autoencoders are commonly used for:
- Dimensionality reduction
- Image noise reduction
- Anomaly detection
- Pretraining for other neural networks
They are a powerful tool in representation learning, especially when labeled data is limited.
Conclusion
Machine learning is not just a buzzword—it’s a pivotal technology shaping the future of business, science, healthcare, entertainment, and beyond. By enabling systems to learn from data, adapt to new inputs, and perform human-like tasks, ML opens up a world of possibilities. However, it also demands responsibility, especially in handling data ethically, ensuring fairness, and maintaining Transparency.
As we move further into a data-driven era, understanding how machine learning works becomes essential—not just for engineers or scientists, but for anyone who uses or interacts with technology in their daily life.
Also read : What Are the Key Benefits and Risks of Artificial Intelligence?
FAQs
What is the difference between AI and machine learning?
AI is a broad concept of creating intelligent machines, while machine learning is a subset of AI that focuses on training machines to learn from data.
Do you need to know coding to learn machine learning?
While basic coding knowledge (especially in Python) helps, there are many tools with visual interfaces that allow beginners to experiment without writing code.
What are the most popular programming languages for machine learning?
Python, R, and Julia are commonly used. Python is the most popular due to its rich ecosystem of ML libraries like Scikit-learn, TensorFlow, and PyTorch.
Can machine learning models be 100% accurate?
No model is perfect. Overfitting, bias in data, and randomness in real-world events mean models will always have a margin of error.
Is machine learning only for big companies?
No. Thanks to cloud services and open-source tools, even small businesses and individual developers can build machine learning models.
How long does it take to build a machine learning model?
It depends on the complexity of the task. A simple model may take hours to build, while complex systems can take weeks or months.
What is deep learning, and how is it different from machine learning?
Deep learning is a subset of machine learning that uses neural networks with many layers (deep neural networks) to model complex patterns in data.